
引言:
ChatGPT 从去年11月以来,一直在野蛮增长,直到6月增长见顶。
半年以来有海量的关于AI的想法,中量的试验性产品,以及少量的让人记住的每天使用的产品,以及独一无二的爆款 ChatGPT API。
现在爆款已经越过山丘,生态的每个人都在疑惑:
- 半年了为什么再没有其他爆款产品出来?
- 是不是当前技术遇到了无法不可逾越的鸿沟?
- 作为现在有些迷茫的开发者,之后的方向应该是什么?
这篇文章会通过这半年来多的持续关注的信息思考和一线开发的经验,试图回答这些问题。
本文目录:
- ChatGPT 停止增长
- ChatGPT 作为一款产品合格吗?
- GPT4 当前的技术瓶颈
- 回归产品的本质
- 一个模型还是多个模型?
- Prompt,LLM 的信息通道
- 有了模型和通道之后,开发者能做些什么?
ChatGPT 停止增长
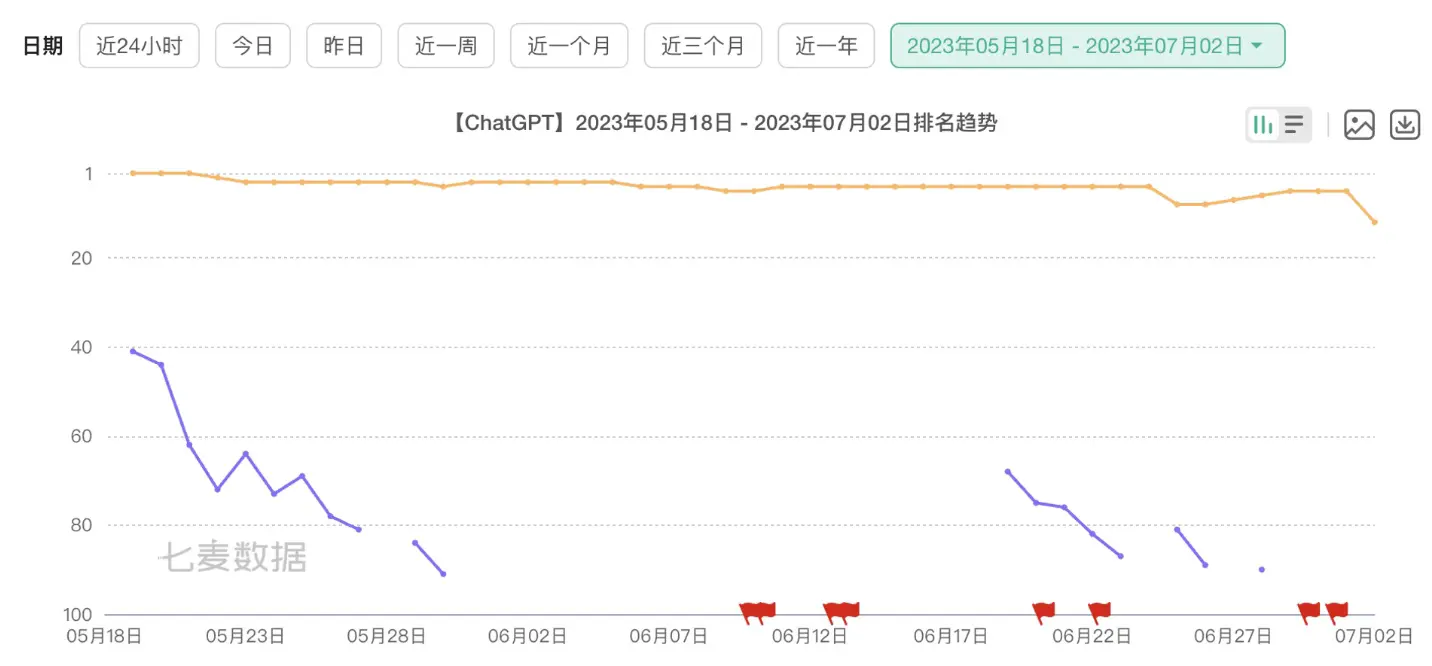
ChatGPT 的网站流量,在5月几乎增长停止,仅增长 2.8% ,6月则开始下降。
在用户最多的美国区,网站排名从48名降到了64名。
尽管官方说 ChatGPT 的流量下降是因为推出了 iOS App,但是 iOS App 在 6月的下载量也开始下降,已经跌出了美国应用总榜单前十,在畅销榜也已经排不上了。
再看上线日和一个月后的续费日的畅销榜排名,从40左右跌到了70左右,可见续费忠诚度也并不太高。
ChatGPT 作为一款产品合格吗?
ChatGPT的产品价值主要是由大语言模型技术所提供的,其次是对话的交互让大家和LLM的沟通门槛降低(了一些)。尽管其技术是全世界最先进的,但界面简单到极致,甚至半年了都几乎还是一个样子,本质上只是自家 API 的套壳,但由于 ChatGPT 的模型本身就是以对话形式作为训练目标的,也可以说是技术自己选择了产品形式。
Sam Altman 自己也承认 ChatGPT 是一款 horrible 的产品。
从数据表现来说,ChatGPT 的人均日使用时长是8分钟,甚至不如 Twitter。ChatGPT 的四周留存是 35% 以上,并且四周之后的下降非常缓慢,证明是一个低频高长留的产品,并不会像抖音这类时间黑洞挤压太多现有应用的空间。

另外 Sam Altman 已经表示,OpenAI 除了 ChatGPT 并不会开发新的产品,因此看起来「做应用层」不是 OpenAI 主要考虑的事情。
因此,创业者在应用层面的空间仍然是巨大的。
- 从竞争方面,OpenAI 的插件系统并不算成功,使用量仅限 Plus 用户,Sam 也说浏览模式之外插件并没有找到 PMF。所以不太需要担心应用被ChatGPT吃掉。
- 从盈利层面,OpenAI 作为行业标杆,选择了用接近成本价的价格来卖API,让API很难成为一个好生意。也让应用层的成本得以保证。
- 从交互层面,对普通人来说,GUI 比 LUI 要好用得多,比如订酒店这件事情,亲自看看图片和评价通过几个点击就可以了,打字输入指令反而是更繁琐的操作。
GPT4 当前的技术瓶颈
ChatGPT 3.5 和 GPT4 本质是去年就训练好的模型,由于涉及到政治舆论压力 GPT5 并未开始训练,而经过这半年多开源社区和其他闭源组织发展情况来看。我们已经能确定的说 GPT4 就是一代技术的最高标准了。那从 GPT4 当前的技术瓶颈,也就是所有LLM当前的技术瓶颈。
- 幻觉
- GPT4 的准确性大幅提高,体现在做题和写代码方面,具体可看前文 《GPT-4 ,通用人工智能的火花》论文内容精选与翻译 。
- 但是幻觉问题依然不可忽视,幻觉一般是体现在某些方面的训练语料不足的时候,模型会胡编乱造一些内容。虽然错误内容只占一小部分,但是混杂在其他真实内容里,并用流畅的句子写出来,人类是很难鉴别的。
- 通过预训练学习更加全面的预料,能极大的改善幻觉,预训练完成后通过监督学习则改善有限。所以幻觉问题在GPT4训练完成的那一刻就已经确定了,只能等到 GPT5 来改善。
- 解决幻觉所需要的数据,大量存在于私域,并非通过公开的爬取可获得,需要全社会一起合作才有可能,但是这种合作相当于把私有数据公开,公司并非圣贤。
- 信息滞后
- GPT4 训练的数据截止到2021年9月,现在已经是23年7月了。这两年的信息确实是非常可怕的。中间所空缺的信息就会滋生幻觉。人类依靠信息做出判断和控制,新信息的价值是超过旧信息的。
- 其他模型的信息滞后问题要好不少,很多2023年才训练的模型,信息至少是到了今年,但这些模型往往也会参考 GPT4 的结果,这样某种意义上就构成了幻觉循环。
- 还有一个方法是通过连接搜索引擎或数据库来弥补实时性问题,这相当于失忆两年的人,根据几百字的新闻简报来还原故事,能有改善,但是有限。
- 成本
- GPT4 至今是很难申请的,3.5 倒是在6月的时候已经基本满足了需要(微软审批了几乎所有人的申请)。Sam 说今年最大的目标之一就是有足够的资源,让大家都用上 GPT4 。
- 如果 OpenAI 都搞不定资源,其他家公司更是不可能搞定的,这本质上是算力的问题,Nvidia 在努力生产了,但是生产速率是恒定的,未来两三年都能计算出来。
- 国内的算力问题更加严重,就不用多展开了。
- GPT4 的价格居高不下,很多个一开始用 GPT4 的产品,最后都不得不回归 3.5。
- 总之可能半年到一年内,大家还是主要用 ChatGPT 3.5 水平的技术,能做任务调度会有一定优势。
- 同质化
- ChatGPT 是爆款,但它是免费可用的,其结果是让其他的模型就生活在其阴影之下。
- Claude 的模型也很棒,但是它的 API 申请难度几乎和 GPT4 不相上下。
- 单纯达到 ChatGPT 水平,已经不具备竞争力了。前几天融资了 13 亿美金的 Pi,宣布其模型已经超过 ChatGPT了,但是它的设计很优雅的产品,在 App Store 总共被下载了 3 万次,非常可怜。
- 所以不要再做 API 套壳了,也只有在有区域限制的地方,还能赚一小波差价。
这些瓶颈背后的技术瓶颈:
- GPT4 已经使用了 MoE 架构,使用多模型堆叠,并在8个模型中选择一个进行输出。
- 使用多模型堆叠而不是一个统一模型,某种程度上说明在数据、算力方面已经遇到了瓶颈。
- 这个瓶颈可能是数据、算力、金钱,这个瓶颈可能比官方宣传的安全性更可能是GPT5未开始训练的原因。
回归产品的本质
产品就是为了满足用户需求而生。有的产品是从现有需求中诞生,有的产品诞生时同时带来了很多需求。但其本质都是为了满足需求,而满足需求就是「为特定的人群提供价值」。
因为人的多样性,没有一款产品能满足所有人的需求,因此不同产品可以服务不同的人群,提供差异化价值。
刚刚提到 GPT4 有 4个瓶颈,幻觉、信息滞后、成本、同质化,如果你能在任何一个瓶颈上有所突破,就可以提供差异化价值。
- 幻觉,通过私有化数据来解决一定的幻觉问题,虽然不能全部解决,但只要有明显提升,依然能跑出垂直领域的优势产品。
- 信息滞后,通过搜索和数据库补充信息,使用调度策略来查询自己的信息和模型信息,
- 成本, GPT4 依然昂贵,尽管 ChatGPT 3.5 已经是成本价,但也是有成本的,通过 cache 重复 query 可以进一步降低成本,配合模型调度策略可以仅在需要时才调用 GPT4。
- 同质化,ChatGPT 的模型看似全知全能,其实定位是「工作助理」,理性、安全、无情感。如果你有一个和ChatGPT定位不一样的垂类模型,能满足其他人群的需求,就能提供差异化的价值。
一个模型还是多个模型?
模型最终是为了产品应用而存在。虽然行业里大家天天把AGI挂在嘴边,但是去做产品的时候,获取用户的时候,拿投资的时候,还是得讲应用。
回到本质,看似全能的 ChatGPT 本质上也不过是个工作助理的垂直应用场景模型而已。过去半年,几乎所有的大模型都在朝着这个方向演进,蒸馏、刷分、PR,是件挺无聊的事情。
人是复杂的生命体,人或者的目的不仅是工作,除了工作助理的方向,人类还有很多的需求,情绪的,情感的,娱乐的,幻想的,这些方面 ChatGPT 做的都不好。
明明人类每天花时间做最多的事情是内容消费,为什么一定要集中卷生产力呢?
在中国愿意为了生产力付费的人有多少呢?
如果 HER 里的 AI 只能收发邮件、安排行程,还会有后面那些故事吗?
所以在应用方向相对垂直的大模型,其应用空间可能更大,可以获得的用户更多的喜爱。
但是训练这样的模型,所需要的数据是比工作助理要更难获得的,比如情感AI,所需要的数据是有情感的甚至有些私密的多轮对话,这样的数据书本里没有,公开网络里也没有。
注意这里说的垂直并不是指有很多个垂直大模型,每一个都只在个垂直领域的比较擅长,而是指一些大模型在某些垂直领域的应用比其他模型要更好。这两点有本质的区别。
Prompt,LLM 的信息通道
LLM 将世界上的文本压缩到一个隐性空间里,这个空间的数据已经远远超过人脑的容量(仅100种语言的本身的信息量已经超过人类个体)。面对如此大的信息量,无法直接进行信息传输。
产品要满足人的需求,要把 LLM 的价值传递给人,就需要建立一个通道,这个通道就是 Prompt。
而 Prompt 就是这个通道。Prompt 不是一句话,而应该包含至少CRE三要素:
- Context 场景
- Rules 规则
- Examples 示例
未包含这三部分的 Prompt,所能传输的信息质量很低,随机性很大。就好像老板提了一个模糊的目标,抑或是像用户提了一个模糊的需求。产品经理只有去理解目标和需求的场景,了解内部的外部的规则,通过实际场景里的例子来进行对齐,才能交付一个好的产品。
写 Prompt 是一种需要学习技巧的智力活动,但大部分人是很懒惰的,并不可能每次都写 Prompt,这就衍生出了几种方案: